Most of them are outdated, but provide historical design context.
They are not user documentation and should not be treated as such.
Documentation is available here.
hostdev passthrough
VM Device Passthrough
Summary
This feature will add host device reporting and their passthrough to guests.
Owner VDSM
- name: Martin Polednik
Owner Engine
- name: Martin Betak
Current Status
- Last updated date: Wed June 14 2017
Terminology
- SR-IOV[1] - Single Root I/O Virtualization - technology that allows single device to expose multiple endpoints that can be passed to VMs
- PF - Physical Function - refers to a physical device (possibly supporting SR-IOV)
- VF - Virtual Function - virtual function exposed by SR-IOV capable device
- IOMMU group - unit of isolation created by the kernel IOMMU driver. Each IOMMU group is isolated from other IOMMU groups with respect to DMA. For our purposes, IOMMU groups are a set of PCI devices which may span multiple PCI buses.
- VFIO[2] - Virtual Function I/O - virtualization device driver, replacement of the pci-stub driver
- mdev - mediated devices - devices that are capable of creating and assigning device instances to a VMs (similar to SR-IOV)
Host Requirements
- POWER 8 host (ppc64le) - no additional configuration required
or
- hardware IOMMU support (AMD-Vi, Intel VT-d enabled in BIOS)
- enabled IOMMU support (intel_iommu=on for Intel, amd_iommu=on for AMD in kernel cmdline)
- SR-IOV: SR-IOV capable hardware in bus with enough bandwidth to accomodate VFs
- RHEL7 or newer (kernel >= 3.6)
Virtual GPU Passthrough
Host Side
There are few more requirements, mostly on the device and the operating system:
- the device itself must be mdev capable,
- kernel must be compiled with mdev support (e.g. recent CentOS kernel),
- correct mdev driver for the device must be installed.
The mdev assignment is handled by vdsm hook vdsm-hook-vfio-mdev which should be automatically installed. To query available mdev types, we can use the following bash command:
for device in /sys/class/mdev_bus/*; do
for mdev_type in $device/mdev_supported_types/*; do
MDEV_TYPE=$(basename $mdev_type)
DESCRIPTION=$(cat $mdev_type/description)
echo "mdev_type: $MDEV_TYPE --- description: $DESCRIPTION";
done;
done | sort | uniq
or parse the output of vdsm-client Host hostdevListByCaps and look for ‘mdev’ dictionary containing supported mdev types.
Internally, the hook spawns new mdev instance and adds the mdev XML snippet to the domain XML. After VM is destroyed, it’s mdev instance is removed. We create the device by writing a uuid string to /sys/class/mdev_bus/$DEVICE/mdev_supported_types/$TYPE/create and delete it by writing 1 to /sys/class/mdev_bus/$DEVICE/$UUID/delete. If successful, /sys/class/mdev_bus/$DEVICE/$UUID does not exist after VM is destroyed. The $UUID is generated as UUID v3 with namespace 8524b17c-f0ca-44a5-9ce4-66fe261e5986 and the name of the VM.
Guest Side
The only step required is following vendor documentation. That will, in most cases, consist of installing special guest version of the GPU driver.
Engine Side
Virtual GPU assignment does not use the ‘Host Devices’ subsystem within engine. To assign a device, we must set predefined property (found in VM -> Edit VM -> Custom Properties) called mdev_type to one of the supported types (see the bash snippet above). Do not assign the device itself via Host Devices tab as that will lead to inability of spawning mdev instances.
Physical GPU Passthrough
These steps (host and guest sides) are required for both x86_64 and ppc64le (POWER 8) platforms.
Host side
The device shouldn’t have any host driver attached to it to avoid issues with the host driver unbinding and re-binding to the device[3]. One of the options for this is pci-stub:
- 1) Determine PCI vendor and device ids that need to be bound to pci-stub. This can be done by using
lspci -nnfrom pciutils package.
$ lspci -nn
...
01:00.0 VGA compatible controller [0300]: NVIDIA Corporation GM107GL [Quadro K2200] [10de:13ba] (rev a2)
01:00.1 Audio device [0403]: NVIDIA Corporation Device [10de:0fbc] (rev a1)
...
The vendor:device ids for example GPUs and audio functions are therefore 10de:13ba and 10de:0fbc (as seen in brackets on each line).
- 2) From this, we can add a new option to kernel cmdline. For that, we may use /etc/default/grub, line GRUB_CMDLINE_LINUX:
$ vim /etc/default/grub
...
GRUB_CMDLINE_LINUX="nofb splash=quiet console=tty0 ... pci-stub.ids=10de:13ba,10de:0fbc"
...
- 3) For additional safety, it’s better to blacklist corresponding driver (nouveau in nVidia’s case).
$ vim /etc/default/grub
...
GRUB_CMDLINE_LINUX="nofb splash=quiet console=tty0 ... pci-stub.ids=10de:13ba,10de:0fbc rdblacklist=nouveau"
...
- 4) After refreshing grub config (via
grub2-mkconfig -o /boot/grub2/grub.cfg) and rebooting, the device should be bound to pci-stub driver. This can be verified bylspci -nnk.
$ lspci -nnk
...
01:00.0 VGA compatible controller [0300]: NVIDIA Corporation GM107GL [Quadro K2200] [10de:13ba] (rev a2)
Subsystem: NVIDIA Corporation Device [10de:1097]
Kernel driver in use: pci-stub
01:00.1 Audio device [0403]: NVIDIA Corporation Device [10de:0fbc] (rev a1)
Subsystem: NVIDIA Corporation Device [10de:1097]
Kernel driver in use: pci-stub
...
Guest Side
Inside the guest, only proprietary drivers are supported and therefore oss drivers should be blacklisted.
- 1) Using information from the host, determine whether the GPU is AMD or nVidia.
- 2) Blacklist corresponding driver by adding it to guest’s kernel cmdline.
$ vim /etc/default/grub
...
GRUB_CMDLINE_LINUX="nofb splash=quiet console=tty0 ... rdblacklist=nouveau"
...
- 3) Reboot the guest with GPU present.
Further information can be found at [4].
IOMMU Group Details
“It’s never been a requirement to pass through all devices within an IOMMU group to a guest. IOMMU groups are the unit of isolation and therefore ownership, but VM assignment is still done at the device level. Users may choose to leave some devices in the group unassigned. For instance with Quadro assignment, due to hardware issues with legacy interrupt masking, we do not support assignment of the audio function even though it’s part of the same IOMMU group as the graphics function. For a supported configuration, the audio function should remain unused and unassigned to the VM.”
- Alex Williamson
Engine and Frontend Side
This feature will be accessible only in WebAdmin UI since basic users should not manipulate host and it’s devices. The list of host devices will be visible in Host Sub Tab and in Vm Sub Tab. Vm’s HostDevice SubTab will have the added ability to assign/unassign given host device to VM. 
The assignment of new devices will be facilitated by new dialog (spawned by add host device button). In this dialog user will be able to select one (or more) devices to be attached.
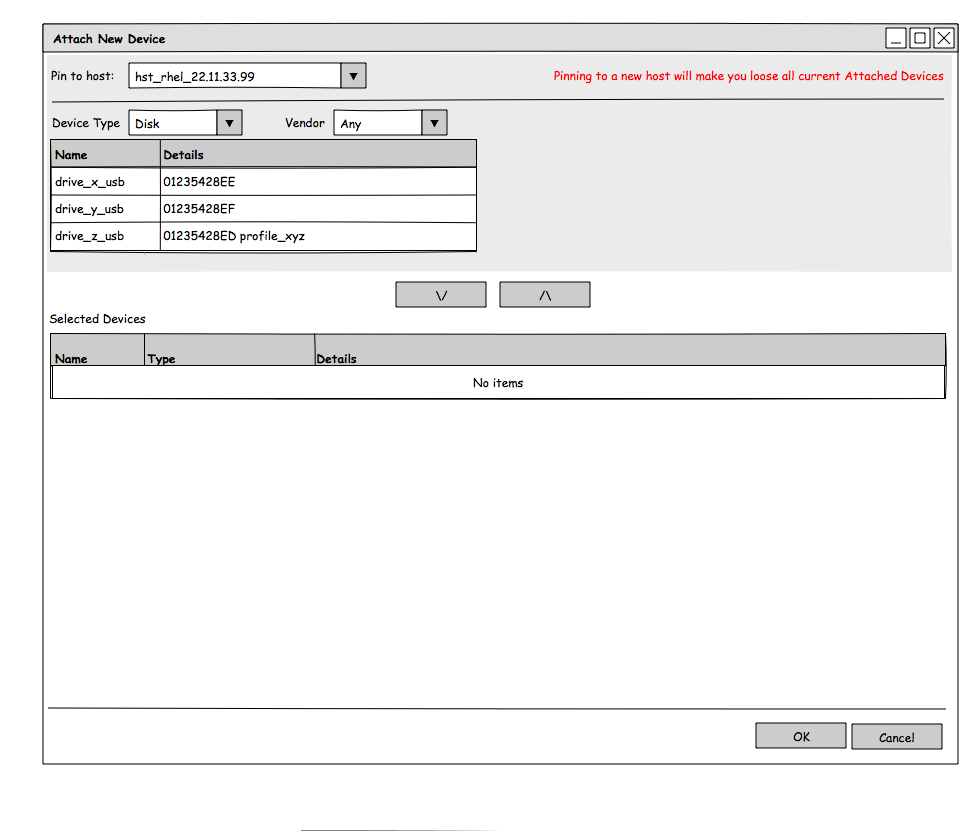
In the dialog table user will also have information about whether particular device is in use by other VMs or to which VMs has this device been attached. The backend will support configuring same host device for multiple vms (an overcommit of a sort), but only one of them will be allowed to run at given time.
The added devices will be shown in the Host Device sub tab. Some items will be greyed out and cannot be removed. Those devices serve as placeholders to satisfy the IOMMU group restriction and will not be attached to guest. User can choose to explicitly add such device (again using Add Device dialog). In that case the device will not be greyed out. Placeholder devices are removed automatically when user removes all devices that enforced the respective placeholders.
VDSM and Host Side
Unlike virtual devices, host passthrough uses real host hardware, making the number of such assigned devices limited. The passthrough capability itself requires hardware that supports intel VT-d or AMD-vi. This capability can be reported through reading /sys/class/iommu and looking for ‘dmar’ file. Iommu also needs to be allowed on the host, which can unreliably be detected by parsing /proc/cmdline for intel_iommu=on or iommu=on.
In order to report state of these devices, new verb is introduced: hostdevListByCaps. The verb takes list as an argument where each element of the list is a string identifying the class of devices caller wants to display (pci, usb_device, usb…). If no classes are specified, all of them are displayed. vdsClient supports hostdevFilterByCaps and displays the devices as a tree. Examples of the format are given below.
Generic:
pci_0000_00_1f_2 = {'params': {'address': {'bus': '0',
'domain': '0',
'function': '2',
'slot': '31'},
'capability': 'pci',
'iommu_group': '11',
'parent': 'computer',
'product': '82801JI (ICH10 Family) SATA AHCI Controller',
'product_id': '0x3a22',
'vendor': 'Intel Corporation',
'vendor_id': '0x8086'}}
PF:
pci_0000_05_00_1 = {'params': {'address': {'bus': '5',
'domain': '0',
'function': '1',
'slot': '0'},
'capability': 'pci',
'iommu_group': '15',
'parent': 'pci_0000_00_09_0',
'product': '82576 Gigabit Network Connection',
'product_id': '0x10c9',
'totalvfs': 7,
'vendor': 'Intel Corporation',
'vendor_id': '0x8086'}}
VF:
pci_0000_05_10_1 = {'params': {'address': {'bus': '5',
'domain': '0',
'function': '1',
'slot': '16'},
'capability': 'pci',
'iommu_group': '22',
'parent': 'pci_0000_00_09_0',
'physfn': 'pci_0000_05_00_1',
'product': '82576 Virtual Function',
'product_id': '0x10ca',
'vendor': 'Intel Corporation',
'vendor_id': '0x8086'}}
Known device classes:
[ compatible ] pci
[incompatible] usb
[ compatible ] usb_device
[ compatible ] scsi
[incompatible] scsi_host
[incompatible] scsi_target
[incompatible] net
[incompatible] storage
When domain with valid hostdev definition in devices section is started, VM tries to detach_detachable() the device. Due to more control on our side, the host devices are running in managed=no mode, meaning the handling of device reset is given to VDSM. The detach_detachable() call takes care of detaching the device from host (unbinding it from current drivers and binding to vfio, or pci-stub if old KVM is used - this behaviour is handled by libvirt’s detachFlags call) and correctly setting permissions for /dev/vfio iommu group endpoint.
The valid hostdev definition is similar to other devices and is documented in vdsm/rpc/vdsmapi-schema.json.
Valid minimal host device definition for device pci_0000_05_10_1:
{..., 'devices': [..., {'type': 'hostdev', 'device': 'pci_0000_05_10_1'}, ...], ...}
detach_detachable details: detachFlag() call spawns new device in /dev/vfio named after device’s iommu group. The group can be read via link /sys/bus/pci/devices/$device_name/iommu_group or libvirt’s nodeDev XML - so for example, /dev/vfio/12 can exist. Qemu needs an access to this device, which by default is set to root:root 0600 mode. VDSM chowns and chmods this file through udev rule to qemu:qemu 0600. VFIO uses iommu group as atomic unit for passthrough, meaning that the whole group has to be attached - this ranges from single device (SR-IOV VF) to multiple devices (GPU + sound card + hub). VDSM uses devices as atomic unit (due to possibility of running single device with unsafe interrupts), attachment of whole groups is left to engine.
When domain with specified hostdev is destroyed, the device is released back to host via the reattach_detachable() call. The call takes care of reattaching the device back to host (meaning unbinding from vfio driver) via libvirt’s reAttach() call and removing udev rule file for given iommu group.
Expected Workflows
VM Creation
- VDSM receives vmCreate command with valid host device definition,
- before XML is generated, the device is
- detached from the host
- and it’s permissions are modified by generated udev rule,
- XML is constructed and VM is started.
The expected outcome is
- Guest is running,
- /dev/vfio/X (where X is iommu group of the device) exists and has qemu:qemu 0600 permissions,
- /etc/udev/rules.d/99-vdsm-iommu_group_X.rules file exists.
VM Removal
- VM is destroyed as ussual,
- cleanup routine takes care of reattaching the device back to host
- related udev rules are cleaned up
The expected outcome is:
- Guest is correctly destroyed,
- host devices are reattached back to the host (meaning no unused /dev/vfio/X endpoints exist),
- udev rules related to iommu groups used are removed from the system.
Parsing libvirt XML of the Device
Host device in the xml isn’t different from other devices, therefore we have to parse it’s
- alias
- address
The address indicates how the device is visible inside the guest.
- Find all host devices,
- construct libvirt name (pci_0000_05_10_1) from the address as seen in XML
- pair to existing device
- or if the device doesn’t exist, add it to VM conf
SR-IOV
SR-IOV capability can be found via /sys/bus/pci/devices/`device_name`/sriov_numvfs and sriov_totalvfs, that indicate the device SHOULD be capable of spawning multiple virtual functions. It is possible that the bus device is connected to doesn’t have enough bandwidth for these virtual functions.
echo 7 > sriov_numvfs
-bash: echo: write error: Cannot allocate memory
dmesg | tail -n 1
[ 9952.612558] igb 0000:07:00.0: SR-IOV: bus number out of range
VFs can be spawned by hostdevChangeNumvfs(device_name, number) call, which spawns number VFs for device_name PF. This call might fail for many reasons, resulting in failure to spawn the VFs. Reasons for failure include not enough bandwidth on the bus to handle multiple devices.
Passthrough of VF is similar to generic passthrough.
API
The API of hostdev feature is defined in vdsm/hostdev.py.
Structures
` device_name `
Structure that represents the libvirt name of the device. Such name looks like pci_0000_00_0 for pci devices, usb_usb1 for usb devices or scsi_0_0_0_0.
` device_params `
{'params': {'address': {'bus': '5',
'domain': '0',
'function': '0',
'slot': '0'},
'capability': 'pci',
'iommu_group': '15',
'parent': 'pci_0000_00_09_0',
'product': '82576 Gigabit Network Connection',
'product_id': '0x10c9',
'totalvfs': 7,
'vendor': 'Intel Corporation',
'vendor_id': '0x8086'}}
Dictionary containing all relevant information about the device as returned by libvirt.
Internal
pci_address_to_name -> domain -> bus -> slot -> function -> device_name
Converts domain, bus, slot and function fields of device_params to device_name.
list_by_caps -> vmContainer -> [String] -> {device_name: device_params}
Where [String] is list of strings of device classes. See “known device classes”.
get_device_params -> device_name -> device_params
detach_detachable -> device_name -> device_params
This call manages all actions required to successfully prepare the device for passthrough incl. detaching it and correcting ownership of the device.
reattach_detachable -> device_name -> ()
This call manages all actiosn required to successfully reattach the device back to host incl. reattaching it and removing udev files managing ownership.
change_numvfs -> device_name -> numvfs -> ()
Where Int ≤ device_params[‘totalvfs’].
External
-
Create VM device definition (minimal):
{‘type’: ‘hostdev’, ‘device’: device_name}
-
hostdevListByCaps -> [String] -> [vmDevice]
Where [String] is list of strings of device classes. See “known device classes”.
hostdevChangeNumvfs -> device_name -> Int -> status
Where Int ≤ device_params[‘totalvfs’].
Cluster (TBD)
Host device structure has 2 fields that are meant to be used as possible implementation of cluster support - vendor_id and product_id. Cluster model and UI could be modified to allow adding these fields as kind of “required devices” - only hosts with those devices would be cluster compatible. This would allow for a migration routine of hotunplug, migrate and hotplug. It might be possible to allow engine to create a device (defined by vendor_id and product_id and identified by name) that would be used as a required device for better UI/UX support.
Migration (TBD)
Migration should be disabled for any VM with hostdev device. This means that in order to migrate the VM, host devices need to be hotunplugged before migration and hotplugged after migration. Whether this routine should be handled by user, engine or VDSM is to be decided.
Migration of network devices IS possible using bonding but that is out of scope for the hostdev support.
Related Bugs
Bug 1196185 - libvirt doesn’t set permissions for VFIO endpoint
Troubleshooting
qemu-kvm: -device vfio-pci,host=NN:NN.N,id=hostdevN,bus=pci.N,addr=0xN: vfio: error opening /dev/vfio/X: Permission denied
qemu-kvm: -device vfio-pci,host=NN:NN.N,id=hostdevN,bus=pci.N,addr=0xN: vfio: failed to get group X
qemu-kvm: -device vfio-pci,host=NN:NN.N,id=hostdevN,bus=pci.N,addr=0xN: Device initialization failed.
qemu-kvm: -device vfio-pci,host=NN:NN.N,id=hostdevN,bus=pci.N,addr=0xN: Device 'vfio-pci' could not be initialized
Error on VDSM side, /dev/vfio/X does not have correct permissions.
qemu-kvm: -device vfio-pci,host=MM:MM.M,id=hostdevM,bus=pci.M,addr=0xM: vfio: error, group X is not viable, please ensure all devices within the iommu_group are bound to their vfio bus driver.
qemu-kvm: -device vfio-pci,host=MM:MM.M,id=hostdevM,bus=pci.M.addr=0xM: vfio: failed to get group X
qemu-kvm: -device vfio-pci,host=MM:MM.M,id=hostdevM,bus=pci.M,addr=0xM: Device initialization failed.
qemu-kvm: -device vfio-pci,host=MM:MM.M,id=hostdevM,bus=pci.M,addr=0xM: Device 'vfio-pci' could not be initialized
You are trying to pass through device that is in IOMMU group with other devices. There are 2 possibilities: either add all other devices from the group or enable unsafe interrupts in vfio_iommu_type1 with allow_unsafe_interrupts=1 (append vfio_iommu_type1.allow_unsafe_interrupts=1 to kernel cmdline). The second solution might lead to vulnerability/instability.
Other: In case of device assignment failure, you can try to allow kernel to reassign devices from BIOS by appending pci=realloc to command line (also solves “not enough MMIO resources for SR-IOV” and other “bad bios” problems).
Known issues
- SR-IOV kind of hostdev currently creates another device instead of updating the hostdev one
- SR-IOV assigns wrong address to a guest
Future planning
Driver Blacklisting / Cmdline
One of the missing pieces in current device assignment functionality is ability to blacklist specific device drivers. This is required for direct GPU assignment, as GPU drivers tend to have issues unbinding from the device (detach routine). At the same time, it might not be feasible to really blacklist (rd.blacklist) a driver, as multiple devices may be present and user might require some of them to be working normally.
The solution is therefore using pci-stub, the null driver able to bind devices based on their (vendor id:product id) tuple. Pci-stub configuration can be specified on kernel cmdline. The functionality to edit cmdline would also open possibilities of adding virtualization specific options such as nestedvt, enabling iommu or specific quirks/hacks (unsafe interrupts come to mind).
Assignment Without Address Exposure
Current state of UI allows pinning a VM to specific host and select the host’s devices for assignment. This is extremely limited and not user friendly. We should allow administrator to define devices (internally represented as (custom name -> (vendor id:product id))) and assign them. Issue with this approach: how do we handle same device on computer with different hw topology (= different iommu groups).
References
Useful Links
- https://libvirt.org/docs/libvirt-appdev-guide-python/en-US/html/libvirt_application_development_guide_using_python-Guest_Domains-Device_Config-PCI_Pass.html
- https://bbs.archlinux.org/viewtopic.php?id=162768 (great post for troubleshooting)
- http://vfio.blogspot.cz/ (Alex Williamson’s blog on VFIO)
[1] https://www.pcisig.com/specifications/iov/
[2] https://www.kernel.org/doc/Documentation/vfio.txt
[3] http://vfio.blogspot.cz/2015/05/vfio-gpu-how-to-series-part-3-host.html